By: Gabrel J. Perin, Runjin Chen, Xuxi Chen, Nina S. T. Hirata, Zhangyang Wang, Junyuan Hong

By: Xinnuo Xu, Rachel Lawrence, Kshitij Dubey, Atharva Pandey, Risa Ueno, Fabian Falck, Aditya V. Nori, Rahul Sharma, Amit Sharma, Javier Gonzalez
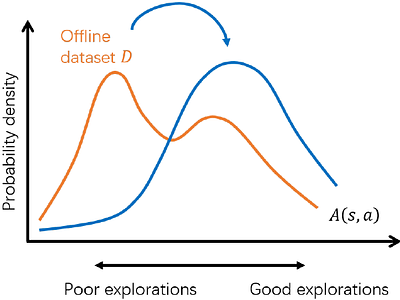
By: Ranting Hu

By: Ivan Marisca, Jacob Bamberger, Cesare Alippi, Michael M. Bronstein
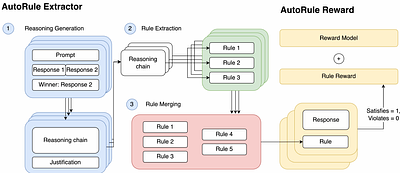
AutoRule: Reasoning Chain-of-thought Extracted Rule-based Rewards Improve Preference Learning
By: Tevin Wang, Chenyan Xiong
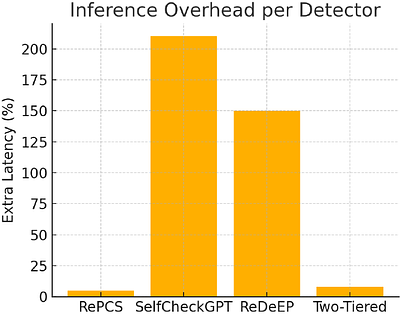
By: Le Vu Anh, Nguyen Viet Anh, Mehmet Dik, Luong Van Nghia
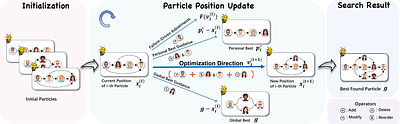
By: Yao Zhang, Chenyang Lin, Shijie Tang, Haokun Chen, Shijie Zhou, Yunpu Ma, Volker Tresp
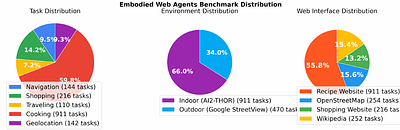
By: Yining Hong, Rui Sun, Bingxuan Li, Xingcheng Yao, Maxine Wu, Alexander Chien, Da Yin, Ying Nian Wu, Zhecan James Wang, Kai-Wei Chang

By: Daewon Kang, YeongHwan Shin, Doyeon Kim, Kyu-Hwan Jung, Meong Hi Son
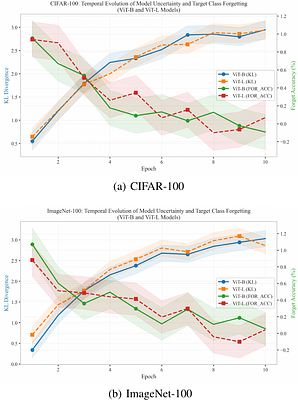
By: Prabhav Sanga, Jaskaran Singh, Arun K. Dubey
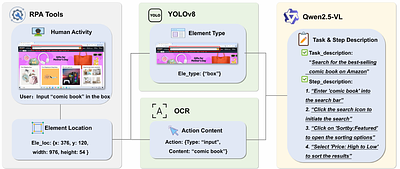
GUI-Robust: A Comprehensive Dataset for Testing GUI Agent Robustness in Real-World Anomalies
By: Jingqi Yang, Zhilong Song, Jiawei Chen, Mingli Song, Sheng Zhou, linjun sun, Xiaogang Ouyang, Chun Chen, Can Wang

Expressive Score-Based Priors for Distribution Matching with Geometry-Preserving Regularization
By: Ziyu Gong, Jim Lim, David I. Inouye
By: Mingkang Zhu, Xi Chen, Zhongdao Wang, Bei Yu, Hengshuang Zhao, Jiaya Jia
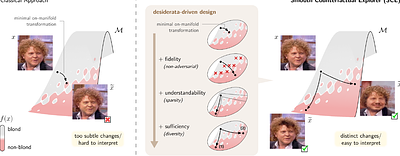
By: Sidney Bender, Jan Herrmann, Klaus-Robert Müller, Grégoire Montavon
By: Nataly Brukhim, Aldo Pacchiano, Miroslav Dudik, Robert Schapire
By: Mohammad Hashemi, Andreas Zufle

By: Jiahao Qiu, Xinzhe Juan, Yimin Wang, Ling Yang, Xuan Qi, Tongcheng Zhang, Jiacheng Guo, Yifu Lu, Zixin Yao, Hongru Wang, Shilong Liu, Xun Jiang, Liu Leqi, Mengdi Wang