
By: Zhengxiang Cheng, Dongping Chen, Mingyang Fu, Tianyi Zhou
Large Reasoning Models (LRMs) have achieved remarkable success, yet they often suffer from producing unnecessary and verbose reasoning chains. We identify a core aspect of this issue as "invalid thinking" -- models tend to repeatedly double-check their work after having derived the correct answer. To address this specific inefficiency, we move beyond the general principles of Efficacy and Efficiency to propose two new, fine-grained principles... more
Large Reasoning Models (LRMs) have achieved remarkable success, yet they often suffer from producing unnecessary and verbose reasoning chains. We identify a core aspect of this issue as "invalid thinking" -- models tend to repeatedly double-check their work after having derived the correct answer. To address this specific inefficiency, we move beyond the general principles of Efficacy and Efficiency to propose two new, fine-grained principles: Brevity, which advocates for eliminating redundancy, and Sufficiency, which ensures critical reasoning steps are preserved. Guided by these principles, we introduce LC-R1, a post-training method based on Group Relative Policy Optimization (GRPO). LC-R1 employs a novel combination of a Length Reward for overall conciseness and a Compress Reward that is specifically designed to remove the invalid portion of the thinking process. Extensive experiments on multiple reasoning benchmarks demonstrate that LC-R1 achieves a significant reduction in sequence length (~50%) with only a marginal (~2%) drop in accuracy, achieving a favorable trade-off point on the Pareto frontier that prioritizes high compression. Our analysis further validates the robustness of LC-R1 and provides valuable insights for developing more powerful yet computationally efficient LRMs. Our code is released at https://github.com/zxiangx/LC-R1. less

By: Edward Li, Zichen Wang, Jiahe Huang, Jeong Joon Park
We present a unified framework for solving partial differential equations (PDEs) using video-inpainting diffusion transformer models. Unlike existing methods that devise specialized strategies for either forward or inverse problems under full or partial observation, our approach unifies these tasks under a single, flexible generative framework. Specifically, we recast PDE-solving as a generalized inpainting problem, e.g., treating forward pre... more
We present a unified framework for solving partial differential equations (PDEs) using video-inpainting diffusion transformer models. Unlike existing methods that devise specialized strategies for either forward or inverse problems under full or partial observation, our approach unifies these tasks under a single, flexible generative framework. Specifically, we recast PDE-solving as a generalized inpainting problem, e.g., treating forward prediction as inferring missing spatiotemporal information of future states from initial conditions. To this end, we design a transformer-based architecture that conditions on arbitrary patterns of known data to infer missing values across time and space. Our method proposes pixel-space video diffusion models for fine-grained, high-fidelity inpainting and conditioning, while enhancing computational efficiency through hierarchical modeling. Extensive experiments show that our video inpainting-based diffusion model offers an accurate and versatile solution across a wide range of PDEs and problem setups, outperforming state-of-the-art baselines. less
4 SciCasts by .

By: Junru Zhang, Lang Feng, Xu Guo, Yuhan Wu, Yabo Dong, Duanqing Xu
Time-series reasoning remains a significant challenge in multimodal large language models (MLLMs) due to the dynamic temporal patterns, ambiguous semantics, and lack of temporal priors. In this work, we introduce TimeMaster, a reinforcement learning (RL)-based method that enables time-series MLLMs to perform structured, interpretable reasoning directly over visualized time-series inputs and task prompts. TimeMaster adopts a three-part structu... more
Time-series reasoning remains a significant challenge in multimodal large language models (MLLMs) due to the dynamic temporal patterns, ambiguous semantics, and lack of temporal priors. In this work, we introduce TimeMaster, a reinforcement learning (RL)-based method that enables time-series MLLMs to perform structured, interpretable reasoning directly over visualized time-series inputs and task prompts. TimeMaster adopts a three-part structured output format, reasoning, classification, and domain-specific extension, and is optimized via a composite reward function that aligns format adherence, prediction accuracy, and open-ended insight quality. The model is trained using a two-stage pipeline: we first apply supervised fine-tuning (SFT) to establish a good initialization, followed by Group Relative Policy Optimization (GRPO) at the token level to enable stable and targeted reward-driven improvement in time-series reasoning. We evaluate TimeMaster on the TimerBed benchmark across six real-world classification tasks based on Qwen2.5-VL-3B-Instruct. TimeMaster achieves state-of-the-art performance, outperforming both classical time-series models and few-shot GPT-4o by over 14.6% and 7.3% performance gain, respectively. Notably, TimeMaster goes beyond time-series classification: it also exhibits expert-like reasoning behavior, generates context-aware explanations, and delivers domain-aligned insights. Our results highlight that reward-driven RL can be a scalable and promising path toward integrating temporal understanding into time-series MLLMs. less
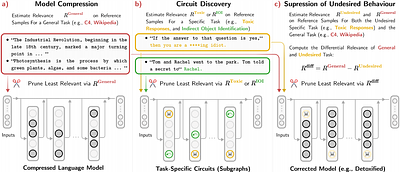
Attribution-guided Pruning for Compression, Circuit Discovery, and Targeted Correction in LLMs
0upvotes
By: Sayed Mohammad Vakilzadeh Hatefi, Maximilian Dreyer, Reduan Achtibat, Patrick Kahardipraja, Thomas Wiegand, Wojciech Samek, Sebastian Lapuschkin
Large Language Models (LLMs) are central to many contemporary AI applications, yet their extensive parameter counts pose significant challenges for deployment in memory- and compute-constrained environments. Recent works in eXplainable AI (XAI), particularly on attribution methods, suggest that interpretability can also enable model compression by identifying and removing components irrelevant to inference. In this paper, we leverage Layer-wi... more
Large Language Models (LLMs) are central to many contemporary AI applications, yet their extensive parameter counts pose significant challenges for deployment in memory- and compute-constrained environments. Recent works in eXplainable AI (XAI), particularly on attribution methods, suggest that interpretability can also enable model compression by identifying and removing components irrelevant to inference. In this paper, we leverage Layer-wise Relevance Propagation (LRP) to perform attribution-guided pruning of LLMs. While LRP has shown promise in structured pruning for vision models, we extend it to unstructured pruning in LLMs and demonstrate that it can substantially reduce model size with minimal performance loss. Our method is especially effective in extracting task-relevant subgraphs -- so-called ``circuits'' -- which can represent core functions (e.g., indirect object identification). Building on this, we introduce a technique for model correction, by selectively removing circuits responsible for spurious behaviors (e.g., toxic outputs). All in all, we gather these techniques as a uniform holistic framework and showcase its effectiveness and limitations through extensive experiments for compression, circuit discovery and model correction on Llama and OPT models, highlighting its potential for improving both model efficiency and safety. Our code is publicly available at https://github.com/erfanhatefi/SparC3. less
4 SciCasts by .