By: Gabrel J. Perin, Runjin Chen, Xuxi Chen, Nina S. T. Hirata, Zhangyang Wang, Junyuan Hong
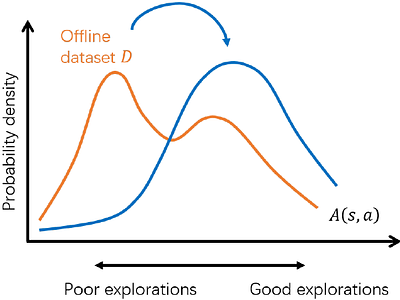
By: Ranting Hu

By: Ivan Marisca, Jacob Bamberger, Cesare Alippi, Michael M. Bronstein
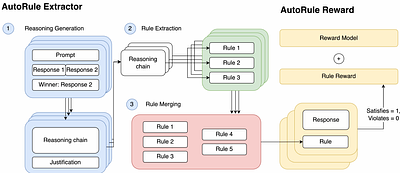
AutoRule: Reasoning Chain-of-thought Extracted Rule-based Rewards Improve Preference Learning
By: Tevin Wang, Chenyan Xiong
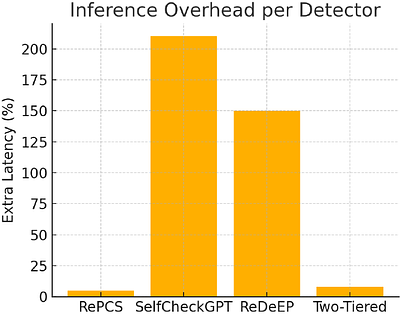
By: Le Vu Anh, Nguyen Viet Anh, Mehmet Dik, Luong Van Nghia
By: Mingkang Zhu, Xi Chen, Zhongdao Wang, Bei Yu, Hengshuang Zhao, Jiaya Jia
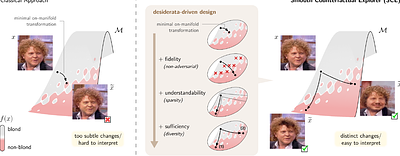
By: Sidney Bender, Jan Herrmann, Klaus-Robert Müller, Grégoire Montavon

By: Junru Zhang, Lang Feng, Xu Guo, Yuhan Wu, Yabo Dong, Duanqing Xu
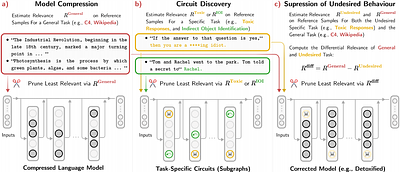
Attribution-guided Pruning for Compression, Circuit Discovery, and Targeted Correction in LLMs
By: Sayed Mohammad Vakilzadeh Hatefi, Maximilian Dreyer, Reduan Achtibat, Patrick Kahardipraja, Thomas Wiegand, Wojciech Samek, Sebastian Lapuschkin
Understanding In-Context Learning on Structured Manifolds: Bridging Attention to Kernel Methods
By: Zhaiming Shen, Alexander Hsu, Rongjie Lai, Wenjing Liao
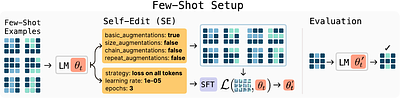
Self-Adapting Language Models
By: Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim, Pulkit Agrawal
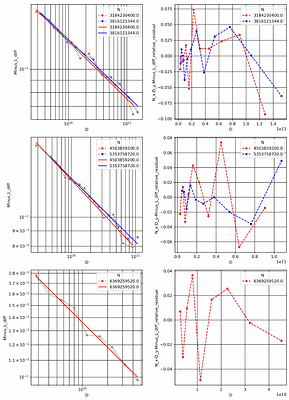
By: Houyi Li, Wenzhen Zheng, Qiufeng Wang, Zhenyu Ding, Haoying Wang, Zili Wang, Shijie Xuyang, Ning Ding, Shuigeng Zhou, Xiangyu Zhang, Daxin Jiang
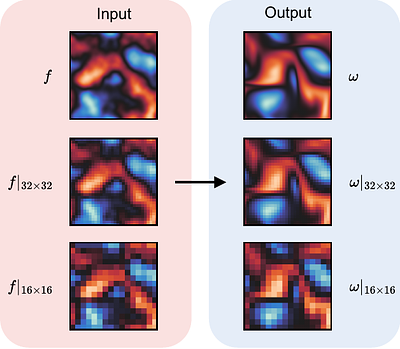
Principled Approaches for Extending Neural Architectures to Function Spaces for Operator Learning
By: Julius Berner, Miguel Liu-Schiaffini, Jean Kossaifi, Valentin Duruisseaux, Boris Bonev, Kamyar Azizzadenesheli, Anima Anandkumar
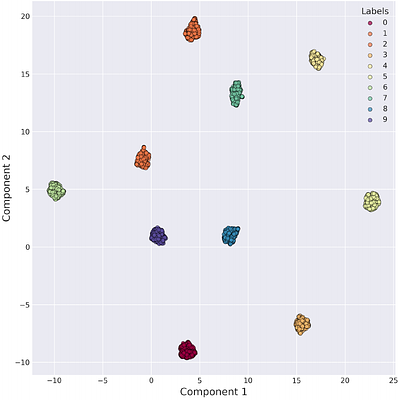
By: Yitao Xu, Tong Zhang, Ehsan Pajouheshgar, Sabine Süsstrunk
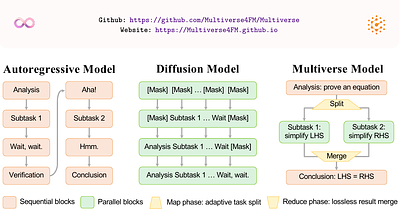
By: Xinyu Yang, Yuwei An, Hongyi Liu, Tianqi Chen, Beidi Chen
By: Tim Z. Xiao, Johannes Zenn, Zhen Liu, Weiyang Liu, Robert Bamler, Bernhard Schölkopf