By: Lorenzo Noci, Chuning Li, Mufan Bill Li, Bobby He, Thomas Hofmann, Chris Maddison, Daniel M. Roy
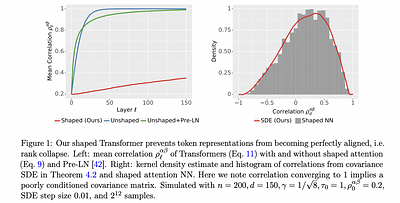
In deep learning theory, the covariance matrix of the representations serves as a proxy to examine the network's trainability. Motivated by the success of Transformers, we study the covariance matrix of a modified Softmax-based attention model with skip connections in the proportional limit of infinite-depth-and-width. We show that at initialization the limiting distribution can be described by a stochastic differential equation (SDE) index... more
In deep learning theory, the covariance matrix of the representations serves as a proxy to examine the network's trainability. Motivated by the success of Transformers, we study the covariance matrix of a modified Softmax-based attention model with skip connections in the proportional limit of infinite-depth-and-width. We show that at initialization the limiting distribution can be described by a stochastic differential equation (SDE) indexed by the depth-to-width ratio. To achieve a well-defined stochastic limit, the Transformer's attention mechanism is modified by centering the Softmax output at identity, and scaling the Softmax logits by a width-dependent
temperature parameter. We examine the stability of the network through the corresponding SDE, showing how the scale of both the drift and diffusion can be elegantly controlled with the aid of residual connections. The existence of a stable SDE implies that the covariance structure is well-behaved, even for very large depth and width, thus preventing the notorious issues of rank degeneracy
in deep attention models. Finally, we show, through simulations, that the SDE provides a surprisingly good description of the corresponding finite-size model. We coin the name shaped Transformer for these architectural modifications.
less
By: Bhan Lam, Julia Chieng, Kenneth Ooi, Zhen-Ting Ong, Karn N. Watcharasupat, Joo Young Hong, Woon-Seng Gan
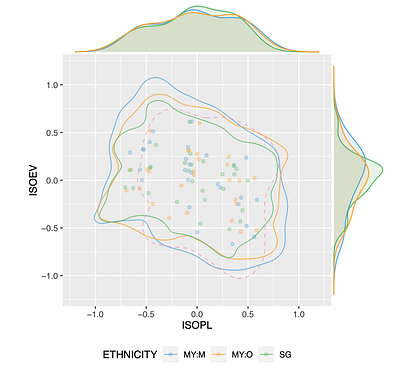
Despite being neighbouring countries and sharing the language of Bahasa Melayu (ISO 639-3:ZSM), cultural and language education policy differences between Singapore and Malaysia led to differences in the translation of the "annoying" perceived affective quality (PAQ) attribute from English (ISO 639-3:ENG) to ZSM. This study expands upon the translation of the PAQ attributes from eng to ZSM in Stage 1 of the Soundscapes Attributes Translation ... more
Despite being neighbouring countries and sharing the language of Bahasa Melayu (ISO 639-3:ZSM), cultural and language education policy differences between Singapore and Malaysia led to differences in the translation of the "annoying" perceived affective quality (PAQ) attribute from English (ISO 639-3:ENG) to ZSM. This study expands upon the translation of the PAQ attributes from eng to ZSM in Stage 1 of the Soundscapes Attributes Translation Project (SATP) initiative, and presents the findings of Stage 2 listening tests that investigated ethnonational differences in the translated ZSM PAQ attributes and explored their circumplexity. A cross-cultural listening test was conducted with 100 ZSM speakers from Malaysia and Singapore using the common SATP protocol. The analysis revealed that Malaysian participants from non-native ethnicities (my:o) showed PAQ perceptions more similar to Singapore (sg) participants than native ethnic Malays (MY:M) in Malaysia. Differences between Singapore and Malaysian groups were primarily observed in stimuli related to water features, reflecting cultural and geographical variations. Besides variations in water source-dominant stimuli perception, disparities between MY:M and SG could be mainly attributed to vibrant scores. The findings also suggest that the adoption of region-specific translations, such as membingitkan in Singapore and menjengkelkan in Malaysia, adequately addressed differences in the annoying attribute, as significant differences were observed in one or fewer stimuli across ethnonational groups The circumplexity analysis indicated that the quasi-circumplex model better fit the data compared to the assumed equal angle quasi-circumplex model in ISO/TS 12913-3, although deviations were observed possibly due to respondents' unfamiliarity with the United Kingdom-centric context of the stimulus dataset. Furthermore, the alignment between Stage 2 listening tests and quantitative evaluation of attributes in Stage 1 revealed biases in the eventful–uneventful dimension across ethnonational groups. This study provides insights into the perception of PAQ attributes in cross-cultural and cross-national contexts, facilitating the culturally appropriate adoption of translated PAQ attributes in soundscapeevaluation.
less
By: Germans Savcisens, Tina Eliassi-Rad, Lars Kai Hansen, Laust Mortensen, Lau Lilleholt, Anna Rogers, Ingo Zettler, Sune Lehmann
Over the past decade, machine learning has revolutionized computers' ability
to analyze text through flexible computational models. Due to their structural
similarity to written language, transformer-based architectures have also shown
promise as tools to make sense of a range of multi-variate sequences from
protein-structures, music, electronic health records to weather-forecasts. We
can also represent human lives in a way that shares this... more
Over the past decade, machine learning has revolutionized computers' ability
to analyze text through flexible computational models. Due to their structural
similarity to written language, transformer-based architectures have also shown
promise as tools to make sense of a range of multi-variate sequences from
protein-structures, music, electronic health records to weather-forecasts. We
can also represent human lives in a way that shares this structural similarity
to language. From one perspective, lives are simply sequences of events: People
are born, visit the pediatrician, start school, move to a new location, get
married, and so on. Here, we exploit this similarity to adapt innovations from
natural language processing to examine the evolution and predictability of
human lives based on detailed event sequences. We do this by drawing on
arguably the most comprehensive registry data in existence, available for an
entire nation of more than six million individuals across decades. Our data
include information about life-events related to health, education, occupation,
income, address, and working hours, recorded with day-to-day resolution. We
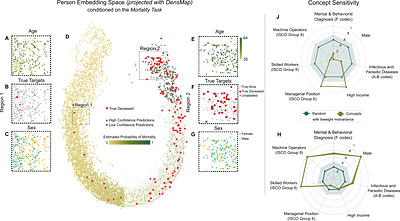
create embeddings of life-events in a single vector space showing that this
embedding space is robust and highly structured. Our models allow us to predict
diverse outcomes ranging from early mortality to personality nuances,
outperforming state-of-the-art models by a wide margin. Using methods for
interpreting deep learning models, we probe the algorithm to understand the
factors that enable our predictions. Our framework allows researchers to
identify new potential mechanisms that impact life outcomes and associated
possibilities for personalized interventions.
less

By: Ralph Foorthuis
Anomalies are occurrences in a dataset that are in some way unusual and do not fit the general patterns. The concept of the anomaly is typically ill-defined and perceived as vague and domain-dependent. Moreover, despite some 250 years of publications on the topic, no comprehensive and concrete overviews of the different types of anomalies have hitherto been published. By means of an extensive literature review this study therefore offers the ... more
Anomalies are occurrences in a dataset that are in some way unusual and do not fit the general patterns. The concept of the anomaly is typically ill-defined and perceived as vague and domain-dependent. Moreover, despite some 250 years of publications on the topic, no comprehensive and concrete overviews of the different types of anomalies have hitherto been published. By means of an extensive literature review this study therefore offers the first theoretically principled and domain-independent typology of data anomalies and presents a full overview of anomaly types and subtypes. To concretely define the concept of the anomaly and its different manifestations, the typology employs five dimensions: data type, cardinality of relationship, anomaly level, data structure, and data distribution. These fundamental and data-centric dimensions naturally yield 3 broad groups, 9 basic types, and 63 subtypes of anomalies. The typology facilitates the evaluation of the functional capabilities of anomaly detection algorithms, contributes to explainable data science, and provides insights into relevant topics such as local versus global anomalies.
less