By: Bhan Lam, Julia Chieng, Kenneth Ooi, Zhen-Ting Ong, Karn N. Watcharasupat, Joo Young Hong, Woon-Seng Gan
Despite being neighbouring countries and sharing the language of Bahasa Melayu (ISO 639-3:ZSM), cultural and language education policy differences between Singapore and Malaysia led to differences in the translation of the "annoying" perceived affective quality (PAQ) attribute from English (ISO 639-3:ENG) to ZSM. This study expands upon the translation of the PAQ attributes from eng to ZSM in Stage 1 of the Soundscapes Attributes Translation ... more
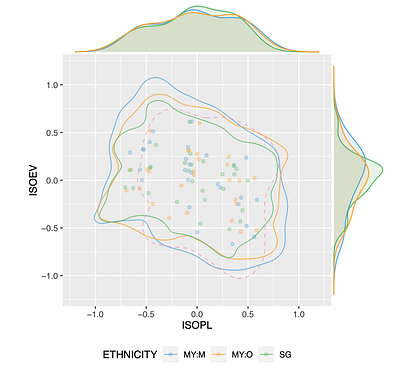
Despite being neighbouring countries and sharing the language of Bahasa Melayu (ISO 639-3:ZSM), cultural and language education policy differences between Singapore and Malaysia led to differences in the translation of the "annoying" perceived affective quality (PAQ) attribute from English (ISO 639-3:ENG) to ZSM. This study expands upon the translation of the PAQ attributes from eng to ZSM in Stage 1 of the Soundscapes Attributes Translation Project (SATP) initiative, and presents the findings of Stage 2 listening tests that investigated ethnonational differences in the translated ZSM PAQ attributes and explored their circumplexity. A cross-cultural listening test was conducted with 100 ZSM speakers from Malaysia and Singapore using the common SATP protocol. The analysis revealed that Malaysian participants from non-native ethnicities (my:o) showed PAQ perceptions more similar to Singapore (sg) participants than native ethnic Malays (MY:M) in Malaysia. Differences between Singapore and Malaysian groups were primarily observed in stimuli related to water features, reflecting cultural and geographical variations. Besides variations in water source-dominant stimuli perception, disparities between MY:M and SG could be mainly attributed to vibrant scores. The findings also suggest that the adoption of region-specific translations, such as membingitkan in Singapore and menjengkelkan in Malaysia, adequately addressed differences in the annoying attribute, as significant differences were observed in one or fewer stimuli across ethnonational groups The circumplexity analysis indicated that the quasi-circumplex model better fit the data compared to the assumed equal angle quasi-circumplex model in ISO/TS 12913-3, although deviations were observed possibly due to respondents' unfamiliarity with the United Kingdom-centric context of the stimulus dataset. Furthermore, the alignment between Stage 2 listening tests and quantitative evaluation of attributes in Stage 1 revealed biases in the eventful–uneventful dimension across ethnonational groups. This study provides insights into the perception of PAQ attributes in cross-cultural and cross-national contexts, facilitating the culturally appropriate adoption of translated PAQ attributes in soundscapeevaluation.
less

By: Ralph Foorthuis
Anomalies are occurrences in a dataset that are in some way unusual and do not fit the general patterns. The concept of the anomaly is typically ill-defined and perceived as vague and domain-dependent. Moreover, despite some 250 years of publications on the topic, no comprehensive and concrete overviews of the different types of anomalies have hitherto been published. By means of an extensive literature review this study therefore offers the ... more
Anomalies are occurrences in a dataset that are in some way unusual and do not fit the general patterns. The concept of the anomaly is typically ill-defined and perceived as vague and domain-dependent. Moreover, despite some 250 years of publications on the topic, no comprehensive and concrete overviews of the different types of anomalies have hitherto been published. By means of an extensive literature review this study therefore offers the first theoretically principled and domain-independent typology of data anomalies and presents a full overview of anomaly types and subtypes. To concretely define the concept of the anomaly and its different manifestations, the typology employs five dimensions: data type, cardinality of relationship, anomaly level, data structure, and data distribution. These fundamental and data-centric dimensions naturally yield 3 broad groups, 9 basic types, and 63 subtypes of anomalies. The typology facilitates the evaluation of the functional capabilities of anomaly detection algorithms, contributes to explainable data science, and provides insights into relevant topics such as local versus global anomalies.
less