
By: Luqin Gan, Tarek M. Zikry, Genevera I. Allen
As machine learning systems are increasingly used in high-stakes domains, there is a growing emphasis placed on making them interpretable to improve trust in these systems. In response, a range of interpretable machine learning (IML) methods have been developed to generate human-understandable insights into otherwise black box models. With these methods, a fundamental question arises: Are these interpretations reliable? Unlike with prediction... more
As machine learning systems are increasingly used in high-stakes domains, there is a growing emphasis placed on making them interpretable to improve trust in these systems. In response, a range of interpretable machine learning (IML) methods have been developed to generate human-understandable insights into otherwise black box models. With these methods, a fundamental question arises: Are these interpretations reliable? Unlike with prediction accuracy or other evaluation metrics for supervised models, the proximity to the true interpretation is difficult to define. Instead, we ask a closely related question that we argue is a prerequisite for reliability: Are these interpretations stable? We define stability as findings that are consistent or reliable under small random perturbations to the data or algorithms. In this study, we conduct the first systematic, large-scale empirical stability study on popular machine learning global interpretations for both supervised and unsupervised tasks on tabular data. Our findings reveal that popular interpretation methods are frequently unstable, notably less stable than the predictions themselves, and that there is no association between the accuracy of machine learning predictions and the stability of their associated interpretations. Moreover, we show that no single method consistently provides the most stable interpretations across a range of benchmark datasets. Overall, these results suggest that interpretability alone does not warrant trust, and underscores the need for rigorous evaluation of interpretation stability in future work. To support these principles, we have developed and released an open source IML dashboard and Python package to enable researchers to assess the stability and reliability of their own data-driven interpretations and discoveries. less
By: Xiaoyu Hu, Gengyu Xue, Zhenhua Lin, Yi Yu
Algorithmic fairness has become a central topic in machine learning, and mitigating disparities across different subpopulations has emerged as a rapidly growing research area. In this paper, we systematically study the classification of functional data under fairness constraints, ensuring the disparity level of the classifier is controlled below a pre-specified threshold. We propose a unified framework for fairness-aware functional classifica... more
Algorithmic fairness has become a central topic in machine learning, and mitigating disparities across different subpopulations has emerged as a rapidly growing research area. In this paper, we systematically study the classification of functional data under fairness constraints, ensuring the disparity level of the classifier is controlled below a pre-specified threshold. We propose a unified framework for fairness-aware functional classification, tackling an infinite-dimensional functional space, addressing key challenges from the absence of density ratios and intractability of posterior probabilities, and discussing unique phenomena in functional classification. We further design a post-processing algorithm, Fair Functional Linear Discriminant Analysis classifier (Fair-FLDA), which targets at homoscedastic Gaussian processes and achieves fairness via group-wise thresholding. Under weak structural assumptions on eigenspace, theoretical guarantees on fairness and excess risk controls are established. As a byproduct, our results cover the excess risk control of the standard FLDA as a special case, which, to the best of our knowledge, is first time seen. Our theoretical findings are complemented by extensive numerical experiments on synthetic and real datasets, highlighting the practicality of our designed algorithm. less
By: Lorenzo Noci, Chuning Li, Mufan Bill Li, Bobby He, Thomas Hofmann, Chris Maddison, Daniel M. Roy
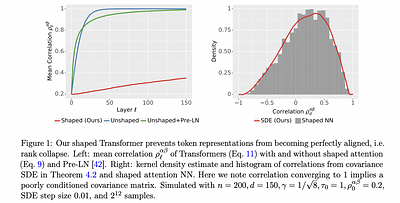
In deep learning theory, the covariance matrix of the representations serves as a proxy to examine the network's trainability. Motivated by the success of Transformers, we study the covariance matrix of a modified Softmax-based attention model with skip connections in the proportional limit of infinite-depth-and-width. We show that at initialization the limiting distribution can be described by a stochastic differential equation (SDE) index... more
In deep learning theory, the covariance matrix of the representations serves as a proxy to examine the network's trainability. Motivated by the success of Transformers, we study the covariance matrix of a modified Softmax-based attention model with skip connections in the proportional limit of infinite-depth-and-width. We show that at initialization the limiting distribution can be described by a stochastic differential equation (SDE) indexed by the depth-to-width ratio. To achieve a well-defined stochastic limit, the Transformer's attention mechanism is modified by centering the Softmax output at identity, and scaling the Softmax logits by a width-dependent
temperature parameter. We examine the stability of the network through the corresponding SDE, showing how the scale of both the drift and diffusion can be elegantly controlled with the aid of residual connections. The existence of a stable SDE implies that the covariance structure is well-behaved, even for very large depth and width, thus preventing the notorious issues of rank degeneracy
in deep attention models. Finally, we show, through simulations, that the SDE provides a surprisingly good description of the corresponding finite-size model. We coin the name shaped Transformer for these architectural modifications.
less
By: Germans Savcisens, Tina Eliassi-Rad, Lars Kai Hansen, Laust Mortensen, Lau Lilleholt, Anna Rogers, Ingo Zettler, Sune Lehmann
Over the past decade, machine learning has revolutionized computers' ability
to analyze text through flexible computational models. Due to their structural
similarity to written language, transformer-based architectures have also shown
promise as tools to make sense of a range of multi-variate sequences from
protein-structures, music, electronic health records to weather-forecasts. We
can also represent human lives in a way that shares this... more
Over the past decade, machine learning has revolutionized computers' ability
to analyze text through flexible computational models. Due to their structural
similarity to written language, transformer-based architectures have also shown
promise as tools to make sense of a range of multi-variate sequences from
protein-structures, music, electronic health records to weather-forecasts. We
can also represent human lives in a way that shares this structural similarity
to language. From one perspective, lives are simply sequences of events: People
are born, visit the pediatrician, start school, move to a new location, get
married, and so on. Here, we exploit this similarity to adapt innovations from
natural language processing to examine the evolution and predictability of
human lives based on detailed event sequences. We do this by drawing on
arguably the most comprehensive registry data in existence, available for an
entire nation of more than six million individuals across decades. Our data
include information about life-events related to health, education, occupation,
income, address, and working hours, recorded with day-to-day resolution. We
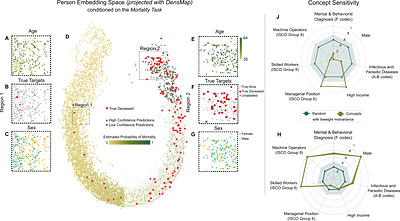
create embeddings of life-events in a single vector space showing that this
embedding space is robust and highly structured. Our models allow us to predict
diverse outcomes ranging from early mortality to personality nuances,
outperforming state-of-the-art models by a wide margin. Using methods for
interpreting deep learning models, we probe the algorithm to understand the
factors that enable our predictions. Our framework allows researchers to
identify new potential mechanisms that impact life outcomes and associated
possibilities for personalized interventions.
less