Automatic pain face analysis in mice: Applied to a varied dataset with non-standardized conditions
Automatic pain face analysis in mice: Applied to a varied dataset with non-standardized conditions
Andresen, N.; Wöllhaf, M.; Wilzopolski, J.; Lang, A.; Wolter, A.; Howe-Wittek, L.; Bekemeier, C.; Pawlak, L.-I.; Beyer, S.; Cynis, H.; Hietel, E.; Rieckmann, V.; Rieckmann, M.; Thöne-Reineke, C.; Lewejohann, L.; Hellwich, O.; Hohlbaum, K.
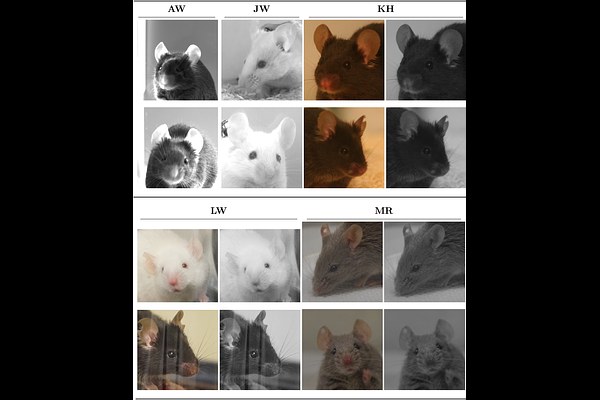
AbstractBiomedical research relies on scientifically validated tools to assess pain, suffering, and distress in laboratory animals to ensure their well-being. In mice, the most frequently used laboratory animals, the Mouse Grimace Scale (MGS) provides a reliable tool for the assessment of facial expression changes caused by impaired well-being. However, no automated tool can yet reliably assess all features of the MGS across different mouse strains under varying experimental or housing conditions in real-time, as the variability present in recorded image datasets poses substantial challenges for computer vision models. Despite this technical difficulty, variability across subsets in terms of mouse strain, treatments, laboratory, and image acquisition setup is essential for paving the way toward MGS assessment under non-standardized conditions in the home cage rather than standardized cage-side recording setups. Against this background, a large and diverse dataset containing five subsets is introduced and a deep learning model was trained to predict the average MGS scores ranging between 0 and 2. It achieved a root mean squared error (RMSE) of 0.26 when trained on all subsets of the dataset, outperforming the average human rater in terms of error magnitude. The correlation between human raters and automated MGS scores was very high (Pearson's r=0.85). In the cross-dataset evaluation, one subset was excluded from training and used for testing the model. This approach yielded higher errors compared to models trained and tested on the same subsets. A model restricted to the feature of orbital tightening showed lower performance than one trained on all facial features of the MGS. Overall, the most reliable model for predicting average MGS scores for a novel dataset is the one trained on the combined subsets. Performance may be further enhanced by fine-tuning the model using human-generated MGS scores for a portion of the novel subset.