ABKD: Pursuing a Proper Allocation of the Probability Mass in Knowledge Distillation via $α$-$β$-Divergence
ABKD: Pursuing a Proper Allocation of the Probability Mass in Knowledge Distillation via $α$-$β$-Divergence
Guanghui Wang, Zhiyong Yang, Zitai Wang, Shi Wang, Qianqian Xu, Qingming Huang
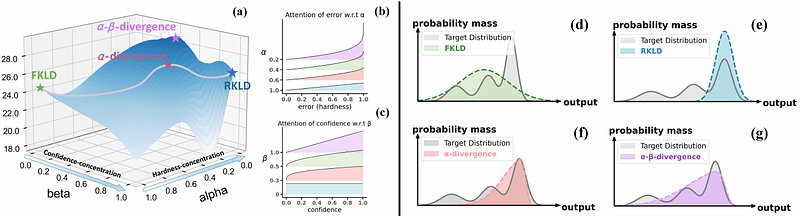
AbstractKnowledge Distillation (KD) transfers knowledge from a large teacher model to a smaller student model by minimizing the divergence between their output distributions, typically using forward Kullback-Leibler divergence (FKLD) or reverse KLD (RKLD). It has become an effective training paradigm due to the broader supervision information provided by the teacher distribution compared to one-hot labels. We identify that the core challenge in KD lies in balancing two mode-concentration effects: the \textbf{\textit{Hardness-Concentration}} effect, which refers to focusing on modes with large errors, and the \textbf{\textit{Confidence-Concentration}} effect, which refers to focusing on modes with high student confidence. Through an analysis of how probabilities are reassigned during gradient updates, we observe that these two effects are entangled in FKLD and RKLD, but in extreme forms. Specifically, both are too weak in FKLD, causing the student to fail to concentrate on the target class. In contrast, both are too strong in RKLD, causing the student to overly emphasize the target class while ignoring the broader distributional information from the teacher. To address this imbalance, we propose ABKD, a generic framework with $\alpha$-$\beta$-divergence. Our theoretical results show that ABKD offers a smooth interpolation between FKLD and RKLD, achieving an effective trade-off between these effects. Extensive experiments on 17 language/vision datasets with 12 teacher-student settings confirm its efficacy. The code is available at https://github.com/ghwang-s/abkd.