DPRM: A Plug-in Doob h transform-induced Token-Ordering Module for Diffusion Language Models
DPRM: A Plug-in Doob h transform-induced Token-Ordering Module for Diffusion Language Models
Dake Bu, Wei Huang, Andi Han, Hau-San Wong, Qingfu Zhang, Taiji Suzuki, Atsushi Nitanda
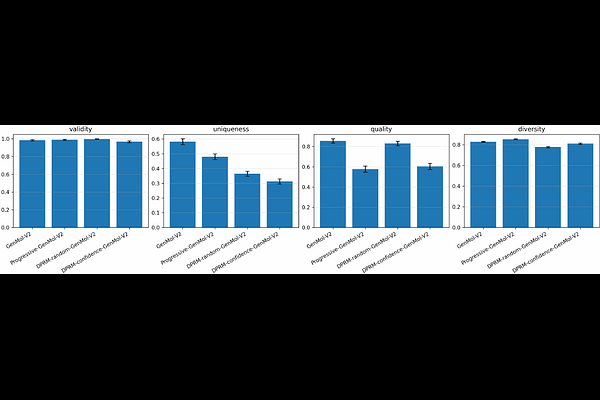
AbstractDiffusion language models generate without a fixed left-to-right order, making token ordering a central algorithmic choice: which tokens should be revealed, retained, revised or verified at each step? Existing systems mainly use random masking or confidence-driven ordering. Random masking creates train--test mismatch, while confidence-only rules are efficient but can be myopic and suppress useful exploration. We introduce DPRM (Doob h-transform Process Reward Model), a plug-in token-ordering module for diffusion language models. DPRM keeps the host architecture, denoising objective and supervision unchanged, and changes only the ordering policy. It starts from confidence-driven progressive ordering and gradually shifts to Doob h transform Process Reward guided ordering through online estimates. We characterize the exact DPRM policy as a reward-tilted Gibbs reveal law, prove O(1/N) convergence of the stagewise Soft-BoN approximation, and show that the online bucketized controller tracks the exact DPRM score at empirical-Bernstein rates. Under tractable optimization assumptions, DPRM also yields a sample-complexity advantage over random and confidence-only ordering. DPRM improves over confidence-based baselines in pretraining, post-training, test-time scaling, and single-cell masked diffusion, with particularly strong gains on harder reasoning subsets. In protein, molecular generation and DNA design, the effect is more multi-objective: ordering-aware variants significantly improve selected structural or fragment-constrained metrics while not uniformly dominating the host baseline on every quality metric. These results identify token ordering as a fundamental control axis in diffusion language models and establish DPRM as a general-purpose module for improving it. Code is available at https://github.com/DakeBU/DPRM-DLLM.