FactReview: Evidence-Grounded Reviews with Literature Positioning and Execution-Based Claim Verification
FactReview: Evidence-Grounded Reviews with Literature Positioning and Execution-Based Claim Verification
Hang Xu, Ling Yue, Chaoqian Ouyang, Libin Zheng, Shaowu Pan, Shimin Di, Min-Ling Zhang
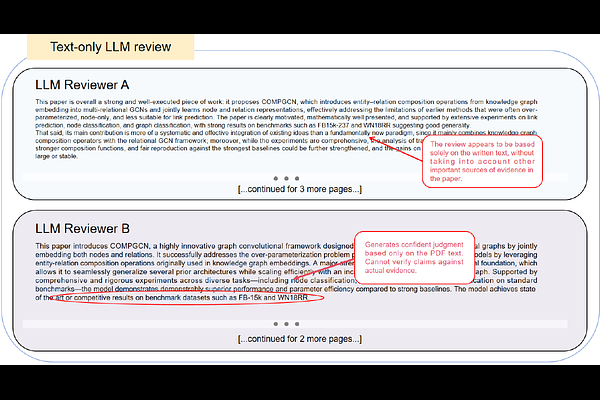
AbstractPeer review in machine learning is under growing pressure from rising submission volume and limited reviewer time. Most LLM-based reviewing systems read only the manuscript and generate comments from the paper's own narrative. This makes their outputs sensitive to presentation quality and leaves them weak when the evidence needed for review lies in related work or released code. We present FactReview, an evidence-grounded reviewing system that combines claim extraction, literature positioning, and execution-based claim verification. Given a submission, FactReview identifies major claims and reported results, retrieves nearby work to clarify the paper's technical position, and, when code is available, executes the released repository under bounded budgets to test central empirical claims. It then produces a concise review and an evidence report that assigns each major claim one of five labels: Supported, Supported by the paper, Partially supported, In conflict, or Inconclusive. In a case study on CompGCN, FactReview reproduces results that closely match those reported for link prediction and node classification, yet also shows that the paper's broader performance claim across tasks is not fully sustained: on MUTAG graph classification, the reproduced result is 88.4%, whereas the strongest baseline reported in the paper remains 92.6%. The claim is therefore only partially supported. More broadly, this case suggests that AI is most useful in peer review not as a final decision-maker, but as a tool for gathering evidence and helping reviewers produce more evidence-grounded assessments. The code is public at https://github.com/DEFENSE-SEU/Review-Assistant.