TopoBench: Benchmarking LLMs on Hard Topological Reasoning
TopoBench: Benchmarking LLMs on Hard Topological Reasoning
Mayug Maniparambil, Nils Hoehing, Janak Kapuriya, Arjun Karuvally, Ellen Rushe, Anthony Ventresque, Noel O'Connor, Fergal Reid
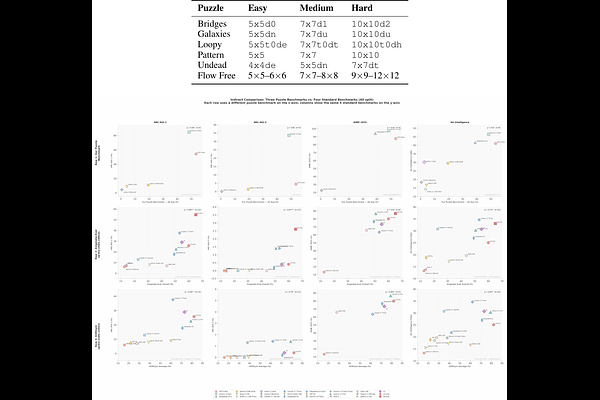
AbstractSolving topological grid puzzles requires reasoning over global spatial invariants such as connectivity, loop closure, and region symmetry and remains challenging for even the most powerful large language models (LLMs). To study these abilities under controlled settings, we introduce TopoBench, a benchmark of six puzzle families across three difficulty levels. We evaluate strong reasoning LLMs on TopoBench and find that even frontier models solve fewer than one quarter of hard instances, with two families nearly unsolved. To investigate whether these failures stem from reasoning limitations or from difficulty extracting and maintaining spatial constraints, we annotate 750 chain of thought traces with an error taxonomy that surfaces four candidate causal failure modes, then test them with targeted interventions simulating each error type. These interventions show that certain error patterns like premature commitment and constraint forgetting have a direct impact on the ability to solve the puzzle, while repeated reasoning is a benign effect of search. Finally we study mitigation strategies including prompt guidance, cell-aligned grid representations and tool-based constraint checking, finding that the bottleneck lies in extracting constraints from spatial representations and not in reasoning over them. Code and data are available at github.com/mayug/topobench-benchmark.