By: Mengwei Hu, Zhengxiong Li, Xianyang Jiang
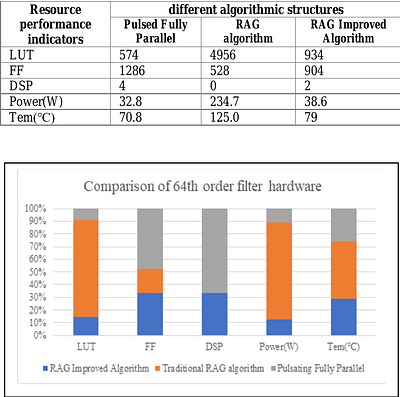
In modern digital filter chip design, efficient resource utilization is a hot topic. Due to the linear phase characteristics of FIR filters, a pulsed fully parallel structure can be applied to address the problem. To further reduce hardware resource consumption, especially related to multiplication functions, an improved RAG algorithm has been proposed. Filters with different orders and for different algorithms have been compared, and the e... more
In modern digital filter chip design, efficient resource utilization is a hot topic. Due to the linear phase characteristics of FIR filters, a pulsed fully parallel structure can be applied to address the problem. To further reduce hardware resource consumption, especially related to multiplication functions, an improved RAG algorithm has been proposed. Filters with different orders and for different algorithms have been compared, and the experimental results show that the improved RAG algorithm excels in terms of logic resource utilization, resource allocation, running speed, and power consumption under various application scenarios. The proposed algorithm introduces a better circuit structure for FIR filters, fully leveraging resource allocation strategies to reduce logic resource consumption. The proposed circuit is faster and more stable, making it suitable for a variety of complex application scenarios. less
By: Victor Gao, Issam Hammad, Kamal El-Sankary, Jason Gu
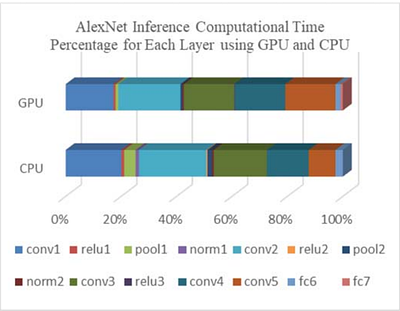
This paper presents a novel method to boost the performance of CNN inference accelerators by utilizing subtractors. The proposed CNN preprocessing accelerator relies on sorting, grouping, and rounding the weights to create combinations that allow for the replacement of one multiplication operation and addition operation by a single subtraction operation when applying convolution during inference. Given the high cost of multiplication in ter... more
This paper presents a novel method to boost the performance of CNN inference accelerators by utilizing subtractors. The proposed CNN preprocessing accelerator relies on sorting, grouping, and rounding the weights to create combinations that allow for the replacement of one multiplication operation and addition operation by a single subtraction operation when applying convolution during inference. Given the high cost of multiplication in terms of power and area, replacing it with subtraction allows for a performance boost by reducing power and area. The proposed method allows for controlling the trade-off between performance gains and accuracy loss through increasing or decreasing the usage of subtractors. With a rounding size of 0.05 and by utilizing LeNet-5 with the MNIST dataset, the proposed design can achieve 32.03% power savings and a 24.59% reduction in area at the cost of only 0.1% in terms of accuracy loss. less
By: Ahmad Houraniah, H. Fatih Ugurdag, Furkan Aydin
Summing a set of numbers, namely, "Accumulation," is a subtask within many computational tasks. If the numbers to sum arrive non-stop in back-to-back clock cycles at high clock frequencies, summing them without allowing them to pile up can be quite a challenge, that is, when the latency of addition (i.e., summing two numbers) is longer than one clock cycle, which is always the case for floating-point numbers. This could also be the case for... more
Summing a set of numbers, namely, "Accumulation," is a subtask within many computational tasks. If the numbers to sum arrive non-stop in back-to-back clock cycles at high clock frequencies, summing them without allowing them to pile up can be quite a challenge, that is, when the latency of addition (i.e., summing two numbers) is longer than one clock cycle, which is always the case for floating-point numbers. This could also be the case for integer summations with high clock frequencies. In the case of floating-point numbers, this is handled by pipelining the adder, but that does not solve all problems. The challenges include optimization of speed, area, and latency. As well as the adaptability of the design to different application requirements, such as the ability to handle variable-size subsequent data sets with no time gap in between and with results produced in the input-order. All these factors make designing an efficient floating-point accumulator a non-trivial problem. Integer accumulation is a relatively simpler problem, where high frequencies can be achieved by using carry-save tree adders. This can then be further improved by efficient resource-sharing. In this paper, we present two fast and area-efficient accumulation circuits, JugglePAC and INTAC. JugglePAC is tailored for floating-point reduction operations (such as accumulation) and offers significant advantages with respect to the literature in terms of speed, area, and adaptability to various application requirements. INTAC is designed for fast integer accumulation. Using carry-save adders and resource-sharing, it can achieve very high clock frequencies while maintaining a low area complexity. less